
There's this take that floats around AI Twitter with way too much confidence:
"Quantization kills quality. You want good outputs? FP16 or higher. End of story."
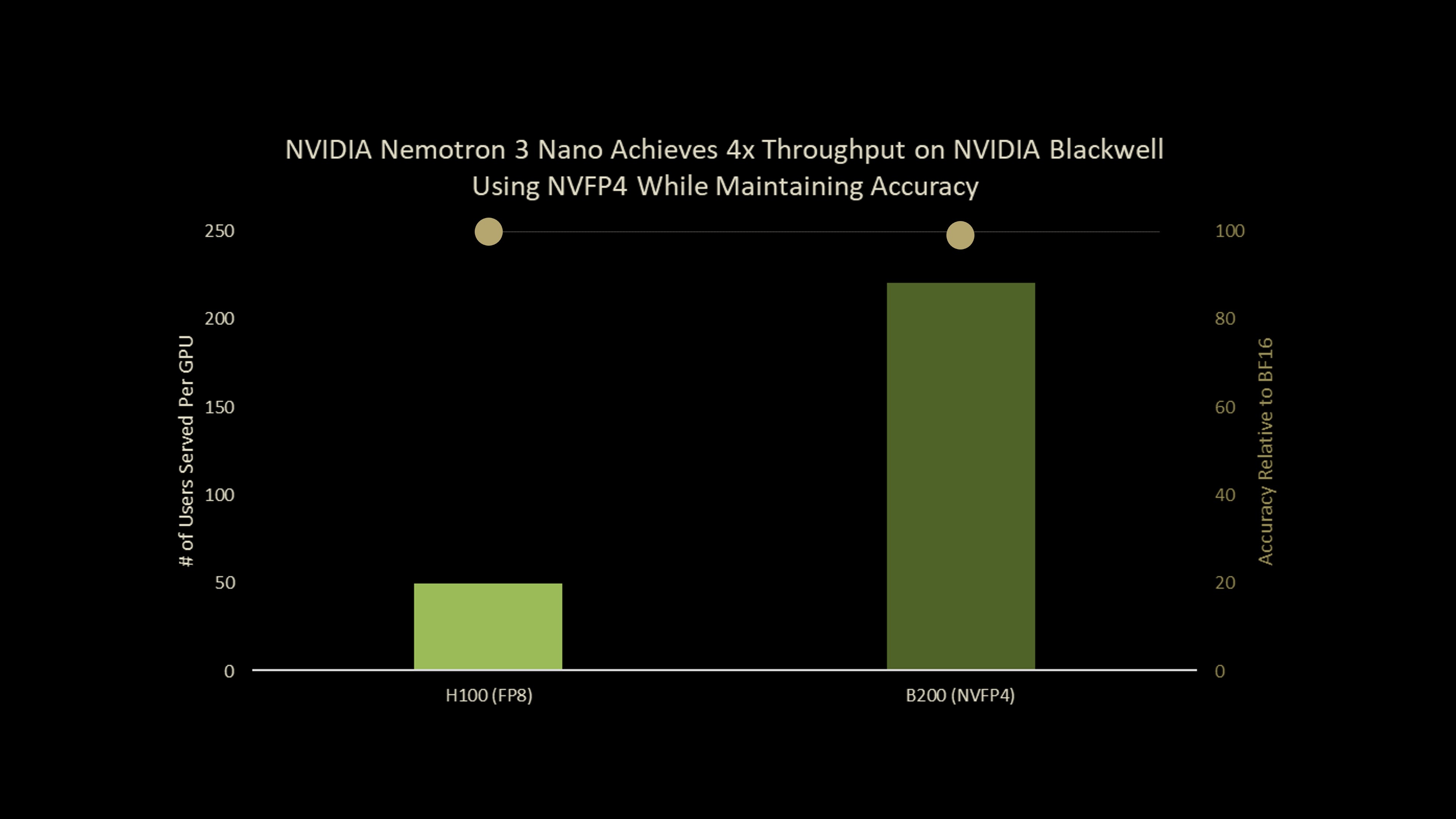
Yesterday, NVIDIA published data that should bury this one for good.
Their new Nemotron 3 Nano running NVFP4 (4-bit floating point) loses less than 1 point on MMLU-Pro versus the full BF16 baseline. Graduate-level science questions? Just over 1 point. Instruction following? Under 1 point.
Oh, and you get 4x FLOPS over BF16 on Blackwell. Plus 1.7x memory savings over FP8.
The quantization-kills-quality era is dead. Here's what's actually going on.
Less Than 1 Point Drop on Most Benchmarks
Nemotron 3 Nano. 30B total parameters, 3.5B active. Here's what NVIDIA published:
| Benchmark | BF16 | NVFP4 | Gap |
|---|---|---|---|
| MMLU-Pro (general knowledge) | 78.3% | 77.4% | -0.9 |
| GPQA Diamond (grad-level science) | 73.0% | 71.9% | -1.1 |
| IFBench (instruction following) | 71.5% | 70.7% | -0.8 |
| AIME25 (hard math) | 89.1% | 86.7% | -2.4 |
Most tasks: 1-3 point gaps. General knowledge and instruction following: under 1.
What you get back: 4x FLOPS over BF16 on Blackwell. 1.7x memory savings over FP8. Enough headroom to run Nemotron 3 Nano locally on an RTX 5090.
A year ago this would've sounded like cope. Now there's a PDF with charts.
NVFP4 is a Scalpel, Not a Sledgehammer
Old-school quantization was a sledgehammer. Reduce precision uniformly across every layer. Every weight, every activation, same treatment. Of course it hurt quality.
NVFP4 is a scalpel.
Here's the thing: not all layers carry the same information load. Some do heavy lifting where precision actually matters. Others are basically just passing data through. Treating them identically wastes compute on the latter and hurts the former.
NVFP4 uses smaller block sizes (16 vs 32) for tighter adaptation to local data distributions. Two-level scaling for better dynamic range. And it allocates precision based on actual information content, not convention.
From NVIDIA's technical report:
"The smaller block size enables more localized adaptation to data distributions, while E4M3 scales provide non-power-of-two scaling factors for lower quantization error."
Measure what needs precision. Preserve it. Compress the rest. Turns out this is not that complicated conceptually. Just hard to execute.
Quantization-Aware Distillation Recovers What's Left
For cases where even small drops matter, NVIDIA introduced Quantization-Aware Distillation (QAD). Use the full-precision model as a "teacher" to train the quantized "student" against the teacher's output distribution.
Results on AceReason Nemotron after QAD:
| Method | AIME24 | AIME25 |
|---|---|---|
| BF16 Baseline | 73.0% | 63.5% |
| NVFP4 (raw) | 69.4% | 58.7% |
| NVFP4 + QAD | 71.7% | 62.0% |
QAD recovers most of the gap. And here's the wild part: it works even with incomplete training data. Train with only math data, model still recovers on code. The teacher's output distribution carries implicit knowledge that transfers across domains.
Kind of beautiful if you think about it.
3x More Successful Completions for the Same Spend
Here's where the quantization-kills-quality crowd completely misses the plot.
They're optimizing for the wrong thing. They look at accuracy per request. The metric that actually matters? Tasks completed per dollar.
Some napkin math.
NVIDIA says NVFP4 enables 4x FLOPS over BF16 on Blackwell. Same GPU, same power, 4x the work. Be conservative and call it 3x effective throughput after real-world overhead. That's 3x more inference per dollar.
Say you lose 2 points of accuracy on a reasoning benchmark. 89% down to 87%.
BF16
100 attempts at 89% accuracy
Expected successes: 89
NVFP4
300 attempts at 87% accuracy
Expected successes: 261
That's not "slightly worse with cost savings." That's 3x more successful completions for the same spend.
That's a no brainer trade.
And that's before you factor in what you can actually do with that headroom:
- Run multiple attempts, pick the best. Majority voting across 3 NVFP4 runs beats a single BF16 run almost every time.
- Longer reasoning chains. More tokens per problem often matters more than base model precision.
- Serve more users. 3x capacity means 3x customers at the same infrastructure cost.
The "quality loss" framing ignores that inference is almost always budget-constrained. Nobody has infinite compute. The question isn't "which is more accurate per request?" It's "which approach solves more problems with my actual budget?"
NVFP4 wins that by a landslide.
We Already Demonstrated 12-37x Faster FLUX Inference with NVFP4
We've been deep in NVFP4 optimization at Fleek for months. Not because we predicted this exact release, but because the physics made sense. Blackwell silicon has incredible FP4 tensor cores. The official tools just weren't generating the right graph patterns to actually use them.
So we went digging. Into nvfuser commits. TensorRT internals. Half-documented code paths. Found the fast paths that light up those tensor cores.
The results, from our 2026 outlook:
100-300
iterations/sec on FLUX.1-dev
~8
it/s with standard tooling
12-37x
faster on the same hardware
Point is: we've been living in NVFP4 land for a while now. Seeing NVIDIA publish comprehensive benchmarks showing the quality holds up is a big deal for the broader ecosystem. It's one thing when we say it works. It's another when NVIDIA drops a technical report with tables.
BF16 Inference is Now Overpaying and Under-Delivering
If you're running BF16 inference today, you're not just overpaying. You're under-delivering. Same budget on NVFP4 solves 3x more problems.
If you're building agents, this is massive. Agents make hundreds of inference calls per task. 4x throughput at lower cost compounds into completely different product economics.
If you dismissed quantization as "quality loss", you were measuring the wrong thing. Measure tasks completed per dollar and the picture flips.
4-Bit is the Only Path to Sustainable AI Inference
The AI industry burns enormous resources on inference. Most of that spend assumes you need BF16 or higher for quality outputs. If NVFP4 delivers equivalent quality at 4x efficiency, the implications (economic and environmental) are hard to overstate.
From NVIDIA's paper:
"The rapid expansion of large language models has increased the demand for more efficient numerical formats to lower computational cost, memory demand, and energy consumption."
Efficient inference isn't just about margins. It's about whether AI scales sustainably at all.
We've been building toward this at Fleek. Optimizing both model layer and infrastructure layer because we think inference economics will define who wins in this space. NVIDIA publishing these benchmarks just gave everyone more ammunition.
4-bit isn't a compromise anymore. It's the new default.
The receipts are in.
Fleek Launches 4-Bit Inference in Early February
We're launching our inference platform in the first half of February with 4-bit inference on several open source LLMs and diffusion models out of the gate. Custom model optimization (bring any model, we'll run it at 4-bit) coming later in Q1.
If you're curious about what NVFP4 can do for your workloads, or just want to nerd out about quantization and inference optimization, reach out. We're happy to chat.
— Harrison